Final Report
Summary
The goal of our project is to train a Minecraft agent that is able to solve maze problems and find the optimal solution. The maze is a 2d plane with different kinds of grids, including a start grid, an end grid, safe grids, and dangerous grids. The agent starts from the start grid and is aimed to reach the start grid without touching dangerous grids -- the agent will die once stepped on one of those dangerous grids. The agent has four options of action: moving north one grid, moving east one grid, moving south one grid, and moving west one grid.
Over the quarter, we tried to apply several machine learning algorithms to train the agent. At the beginning, we tried deep-Q learning, but the result was not satisfying. Then, we changed our method to compute the reward of each grid after each move and train the agent with the q-table obtained. The outcome is satisfying with this method, the agent is able to find the shortest path to solve a 10*10 maze by completing 100 epochs of training.
Approach
At first, we approached the problem by using deep Q-learning. The learning models we have tried include neural network with fully-connected layers and convolutional neural network. The goal of learning models is to compute the reward of each grid and updates the q-table after the end of each epoch. The agent will be awarded 100 points if the end grid is reached. In addition, for each step the agent takes, 1 point was deducted. This policy is to discourage the agent to take unnecessary steps to make sure that the agent finds the shortest path. Then, if the agent dies, 20 points was deducted. However, when we are training with this method, we observed that the agent tends to walk around in an area near the beginning. After analysing, we found the problem is that the training was stuck on the local maximum of reward. To solve this problem, we tried changing the reward policy. In addition to deduct 1 point for each move, we now award the agent an additional reward proportional to the exploration rate (number of visited grids / total number of grids) after each poch. The new policy discourages the agent from moving back to a past grid; instead, it encourages the agent to explore the girds that have not been reached before. Under this policy, the agent walked furfure away but still got stuck in one area. We consulted the TA Mr. McAleer. We adopted his suggestion, letting the agent start at a random position, so every part of the maze can be explored. By doing this, the agent is able to survive longer in the maze and explore more places. However, the chance for the agent to get to the end point is too low that there is hardly a reward table that is computed after the agent successfully solved the maze. Therefore, it’ll take a long time to have a q-table that is computed after solving the maze for adequate times.
Considering only two weeks left for our project, we changed the reward policy of parameters of the q table approach. For now the available rewards are: -2 for each step made, -50 for stepping on a dangerous grid, +100 for reaching the end grid. The reward also includes the exploration rate as mentioned above. Furthermore, since the end grid is far to reach comparing to dangerous grids, when the end grid is reached, the positive reward will be propagated to the last 5 states; when a dangerous grid is reached, the negative reward will only be propagated to the last 1 state.
Evaluation
The evaluation approaches we used correspond to our goals. We check whether the agent reached the destination. And on reaching the destination, we check whether it is the shortest path. However, the agent is not able to get to the destination at the beginning. That means we need an evaluation method to evaluate the progress the agent has made. After discussing, we think the more moves the agent has made before dying, the more progress the agent has been made, because more moves means that the agent has survived longer, and that indicates the improvement in avoiding the toxic grids, which is a prerequisite for the agent to achieve the endpoint.
Using the q-table training method, we observed that the agent’s exploration rate of the maze for each epoch is generally increasing at first over the training process. Once the agent has learned the way to reach the goal, the agent tries to decrease the extra steps and find the shortest path, thus decreasing the exploration rate.
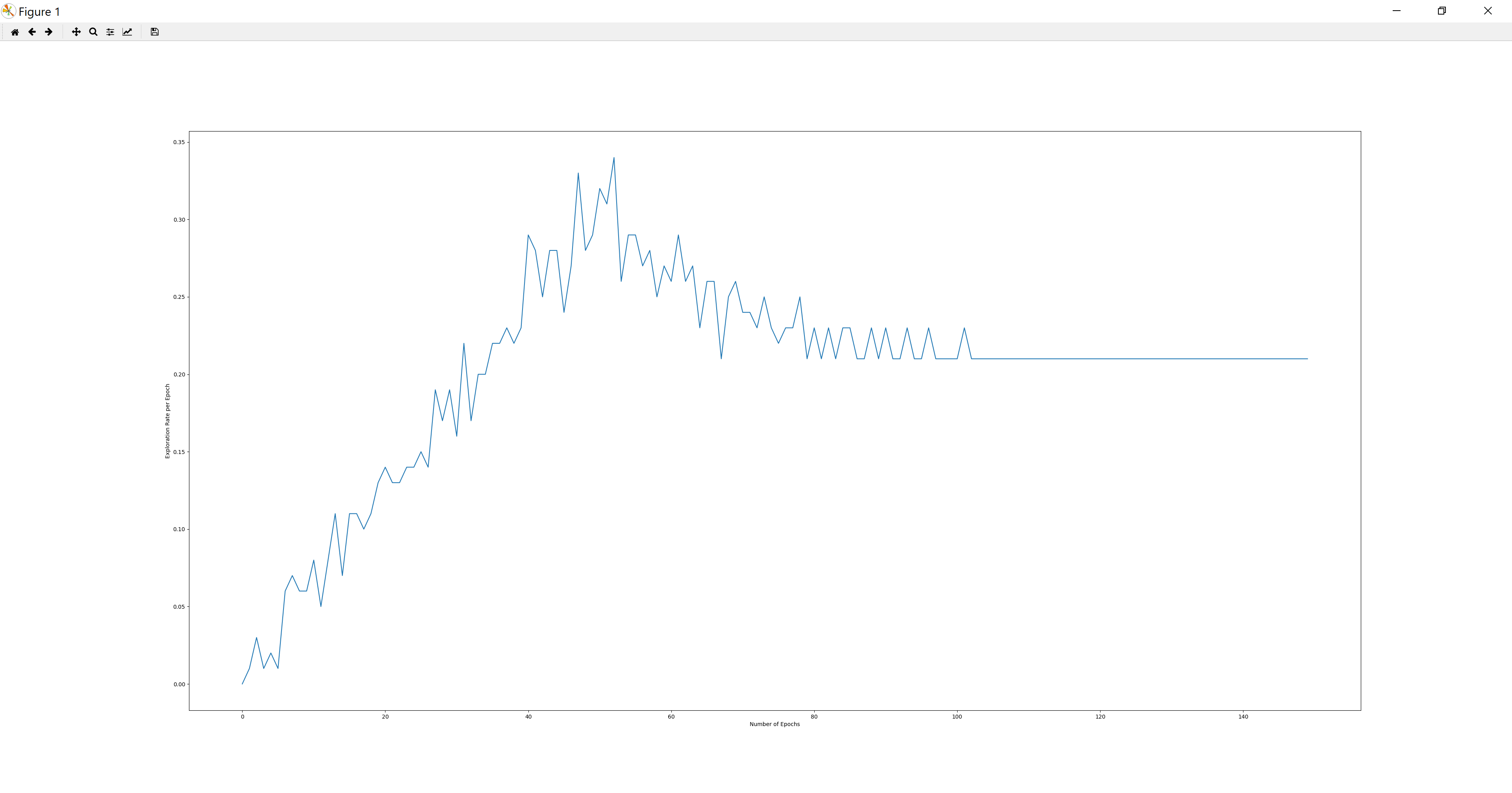
Figure 1. Exploration rate per epoch vs. epochs
During the first several missions, although the agent doesn’t get to the destination, the setting of the maze is becoming more and more clear to the agent. In other words, the agent keeps gaining knowledge about where the safe grids are and where the toxic grids are so the agent can walk further away from the starting point.
Then, after the agent reaches the destination, it will be searching for the shortest path. After the agent’s first arrival at the endpoint, the number of steps for the agent to get to the destination has been declining in the following missions. The reason is that the reward which is brought by a grid closer to the destination is higher than the reward which is brought by an unexplored random grid at most of the time. Since there are still a few grids that are exceptions, the shorestest path we have found so far is suboptimal (very close to the optimal path).
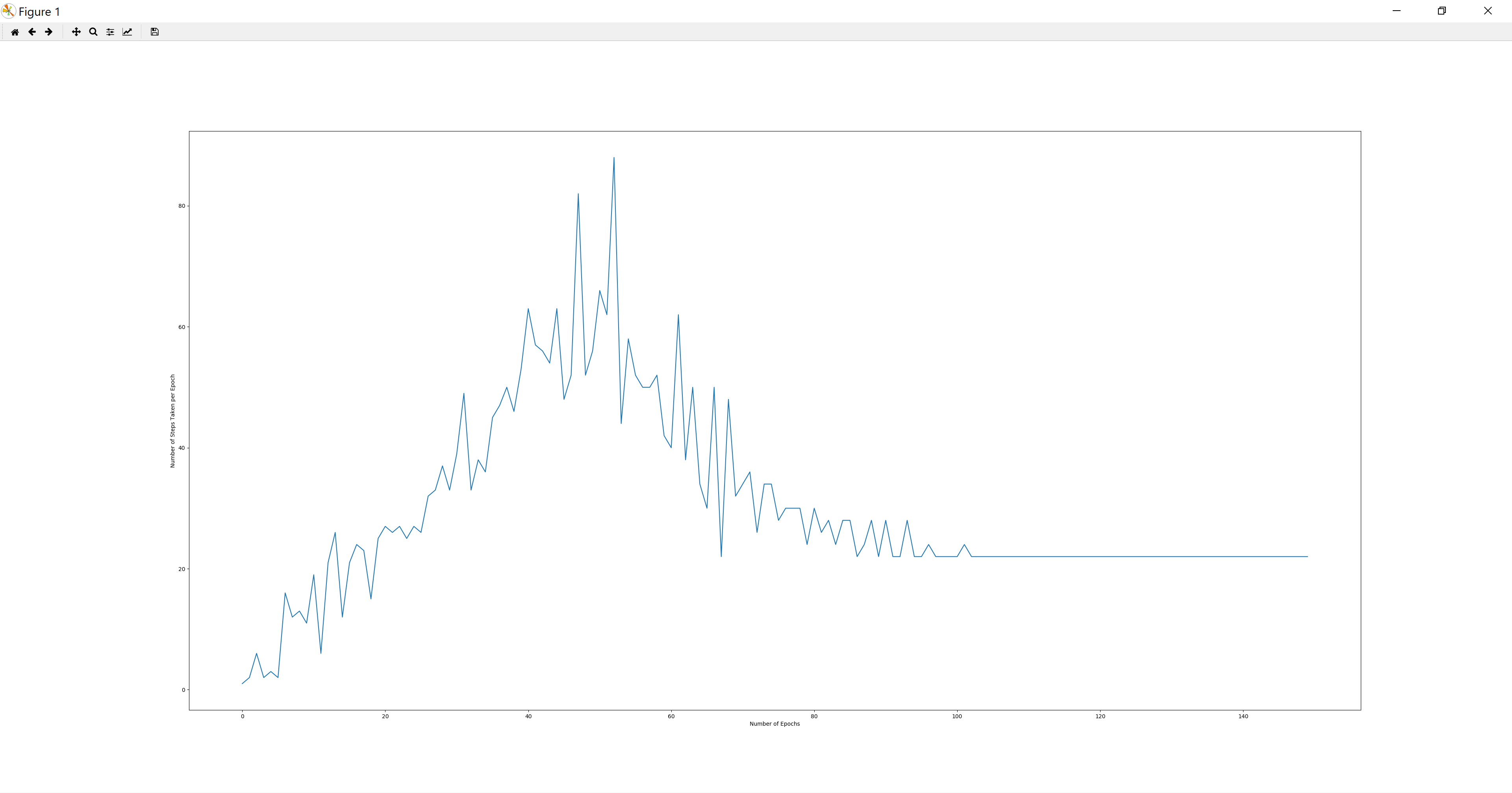
Figure 2. Number of Steps per epoch vs. epochs
The curves of all three figures (Exploration Rate, Number of Steps, Rewards) tend to be horizontal near the end. This means that the agent has found the shortest path that it could found. According to the figures, the number of steps taken at epoch 150 is very close to the length of the shortest path. Also in the last several epochs the agent is able to reach the destination and find the nearly optimal path of a 10x10 maze with approximately 100 missions.
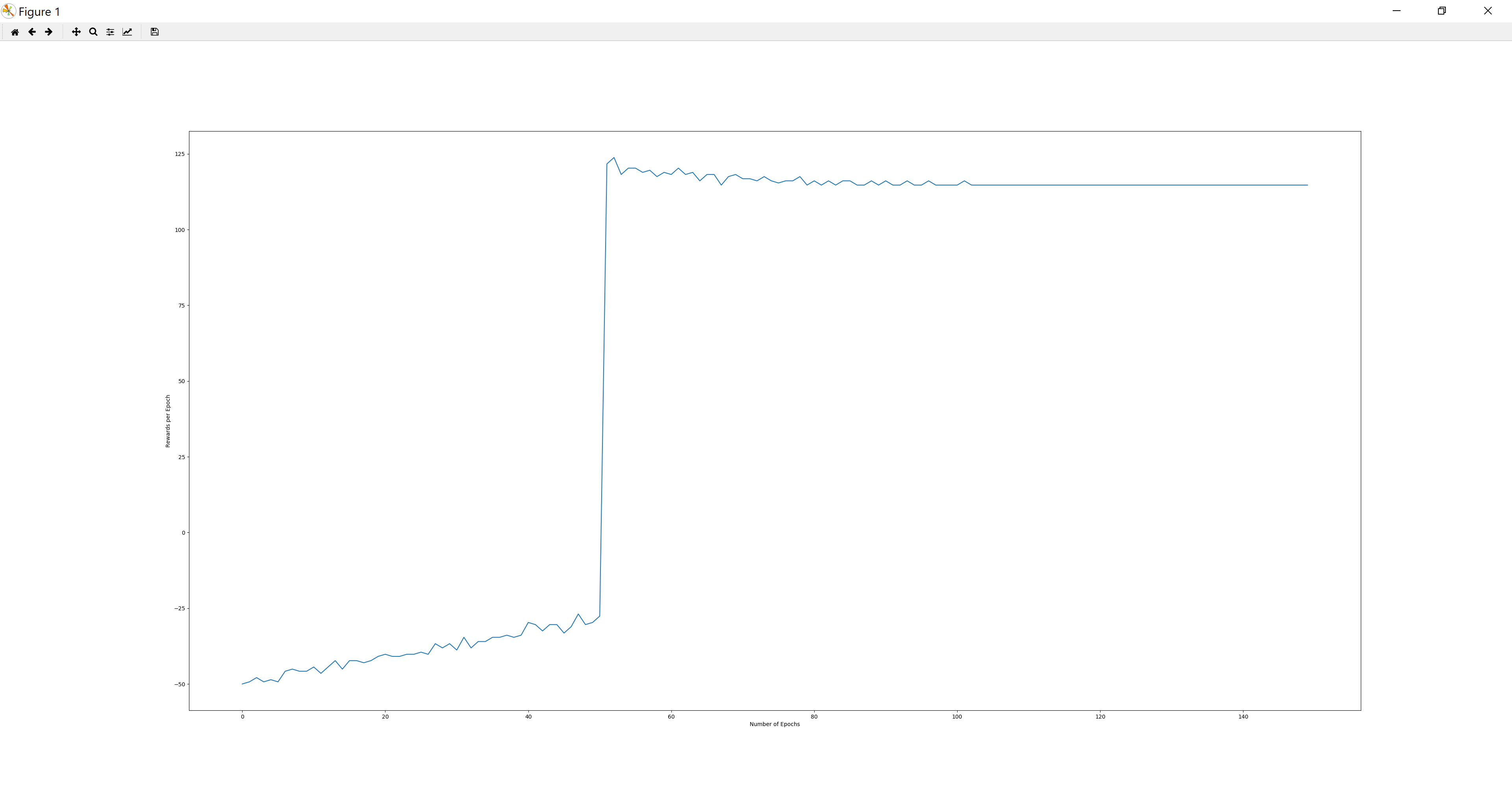
Figure 3. Reward per epoch vs. epochs
Reference
Yusuke S.(2017)Maze Solver source code(Version 1.0)[Source code]. https://github.com/shibuiwilliam/maze_solver